mirror of
https://github.com/UpsilonNumworks/Upsilon.git
synced 2026-05-09 08:25:44 +02:00
[GH-ISSUE #311] Bug with UTF-8 characters in python #138
Labels
No labels
bug
duplicate
easy
enhancement
enhancement
fixed
fixed
good first issue
hard
invalid
pull-request
wontfix
wontfix
No milestone
No project
No assignees
1 participant
Notifications
Due date
No due date set.
Dependencies
No dependencies set.
Reference
starred/Upsilon#138
Loading…
Add table
Add a link
Reference in a new issue
No description provided.
Delete branch "%!s()"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
Originally created by @theodorechle on GitHub (Jan 7, 2023).
Original GitHub issue: https://github.com/UpsilonNumworks/Upsilon/issues/311
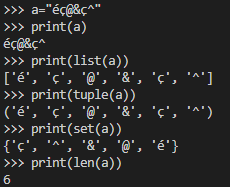
Describe the bug
In UTF-8, many characters are one multiple bytes.
In the python app of the calculator, the len function count the number of bytes and not of characters.
Same for list, tuple and set functions : they create a list, tuple or set with all the bytes.
To Reproduce
If you enter :
a="éç"
list(a)
len(a)
It display :
["e","\u0301","c","\u0327"]
4
Expected behavior
Normally (and I try on Vscode to be sure), len just count the number of characters and not the number of bytes who composed them.
Same for list, tuple and set functions. Normally, you just have the characters inside, but not each byte splitted.
Screenshots
On the calculator:
On Vscode:
Device (please complete the following information):